Accelerating TensorFlow Lite with XNNPACK Integration |
您所在的位置:网站首页 › tensorflow ios › Accelerating TensorFlow Lite with XNNPACK Integration |
Accelerating TensorFlow Lite with XNNPACK Integration
|
https://blog.tensorflow.org/2020/07/accelerating-tensorflow-lite-xnnpack-integration.html
TensorFlow Lite
https://2.bp.blogspot.com/-Fq-o5JrAw6g/XxnJDHEagOI/AAAAAAAADZQ/CUVEpTdONn4JOw8Ffp9FMK8vMZEuSX9_wCLcBGAsYHQ/s1600/mobilephones.png
Leveraging the CPU for ML inference yields the widest reach across the space of edge devices. Consequently, improving neural network inference performance on CPUs has been among the top requests to the TensorFlow Lite team. We listened and are excited to bring you, on average, 2.3X faster floating-point inference through the integration of the XNNPACK libra… TensorFlow Lite · Accelerating TensorFlow Lite with XNNPACK Integration
July 24, 2020
Posted by Marat Dukhan, Google Research
Leveraging the CPU for ML inference yields the widest reach across the space of edge devices. Consequently, improving neural network inference performance on CPUs has been among the top requests to the TensorFlow Lite team. We listened and are excited to bring you, on average, 2.3X faster floating-point inference through the integration of the XNNPACK library into TensorFlow Lite.
To achieve this speedup, the XNNPACK library provides highly optimized implementations of floating-point neural network operators. It launched earlier this year in the WebAssembly backend of TensorFlow.js, and with this release we are introducing additional optimizations tailored to TensorFlow Lite use-cases:
To deliver the greatest performance to TensorFlow Lite users on mobile devices, all operators were optimized for ARM NEON. The most critical ones (convolution, depthwise convolution, transposed convolution, fully-connected), were tuned in assembly for commonly-used ARM cores in mobile phones, e.g. Cortex-A53/A73 in Pixel 2 and Cortex-A55/A75 in Pixel 3.
For TensorFlow Lite users on x86-64 devices, XNNPACK added optimizations for SSE2, SSE4, AVX, AVX2, and AVX512 instruction sets.
Rather than executing TensorFlow Lite operators one-by-one, XNNPACK looks at the whole computational graph and optimizes it through operator fusion. For example, convolution with explicit padding is represented in TensorFlow Lite via a combination of PAD operator and a CONV_2D operator with VALID padding mode. XNNPACK detects this combination of operators and fuses the two operators into a single convolution operator with explicitly specified padding.
The XNNPACK backend for CPU joins the family of TensorFlow Lite accelerated inference engines for mobile GPUs, Android’s Neural Network API, Hexagon DSPs, Edge TPUs, and the Apple Neural Engine. It provides a strong baseline that can be used on all mobile devices, desktop systems, and Raspberry Pi boards.
With the TensorFlow 2.3 release, XNNPACK backend is included with the pre-built TensorFlow Lite binaries for Android and iOS, and can be enabled with a one-line code change. XNNPACK backend is also supported in Windows, macOS, and Linux builds of TensorFlow Lite, where it is enabled via build-time opt-in mechanism. Following wider testing and community feedback, we plan to enable it by default on all platforms in an upcoming release. Performance ImprovementsXNNPACK-accelerated inference in TensorFlow Lite has already been used in Google products in production, and we observed significant speedups across a wide variety of neural network architectures and mobile processors. The XNNPACK backend boosted background segmentation in Pixel 3a Playground by 5X and delivered 2X speedup on neural network models in Augmented Faces API in ARCore.
Accelerating TensorFlow Lite with XNNPACK Integration
July 24, 2020
Posted by Marat Dukhan, Google Research
Leveraging the CPU for ML inference yields the widest reach across the space of edge devices. Consequently, improving neural network inference performance on CPUs has been among the top requests to the TensorFlow Lite team. We listened and are excited to bring you, on average, 2.3X faster floating-point inference through the integration of the XNNPACK library into TensorFlow Lite.
To achieve this speedup, the XNNPACK library provides highly optimized implementations of floating-point neural network operators. It launched earlier this year in the WebAssembly backend of TensorFlow.js, and with this release we are introducing additional optimizations tailored to TensorFlow Lite use-cases:
To deliver the greatest performance to TensorFlow Lite users on mobile devices, all operators were optimized for ARM NEON. The most critical ones (convolution, depthwise convolution, transposed convolution, fully-connected), were tuned in assembly for commonly-used ARM cores in mobile phones, e.g. Cortex-A53/A73 in Pixel 2 and Cortex-A55/A75 in Pixel 3.
For TensorFlow Lite users on x86-64 devices, XNNPACK added optimizations for SSE2, SSE4, AVX, AVX2, and AVX512 instruction sets.
Rather than executing TensorFlow Lite operators one-by-one, XNNPACK looks at the whole computational graph and optimizes it through operator fusion. For example, convolution with explicit padding is represented in TensorFlow Lite via a combination of PAD operator and a CONV_2D operator with VALID padding mode. XNNPACK detects this combination of operators and fuses the two operators into a single convolution operator with explicitly specified padding.
The XNNPACK backend for CPU joins the family of TensorFlow Lite accelerated inference engines for mobile GPUs, Android’s Neural Network API, Hexagon DSPs, Edge TPUs, and the Apple Neural Engine. It provides a strong baseline that can be used on all mobile devices, desktop systems, and Raspberry Pi boards.
With the TensorFlow 2.3 release, XNNPACK backend is included with the pre-built TensorFlow Lite binaries for Android and iOS, and can be enabled with a one-line code change. XNNPACK backend is also supported in Windows, macOS, and Linux builds of TensorFlow Lite, where it is enabled via build-time opt-in mechanism. Following wider testing and community feedback, we plan to enable it by default on all platforms in an upcoming release. Performance ImprovementsXNNPACK-accelerated inference in TensorFlow Lite has already been used in Google products in production, and we observed significant speedups across a wide variety of neural network architectures and mobile processors. The XNNPACK backend boosted background segmentation in Pixel 3a Playground by 5X and delivered 2X speedup on neural network models in Augmented Faces API in ARCore. We found that TensorFlow Lite benefits the most from the XNNPACK backend on small neural network models and low-end mobile phones. Below, we present benchmarks on nine public models covering common computer vision tasks: MobileNet v2 image classification [download] MobileNet v3-Small image classification [download] DeepLab v3 segmentation [download] BlazeFace face detection [download] SSDLite 2D object detection [download] Objectron 3D object detection [download] Face Mesh landmarks [download] MediaPipe Hands landmarks [download] KNIFT local feature descriptor [download]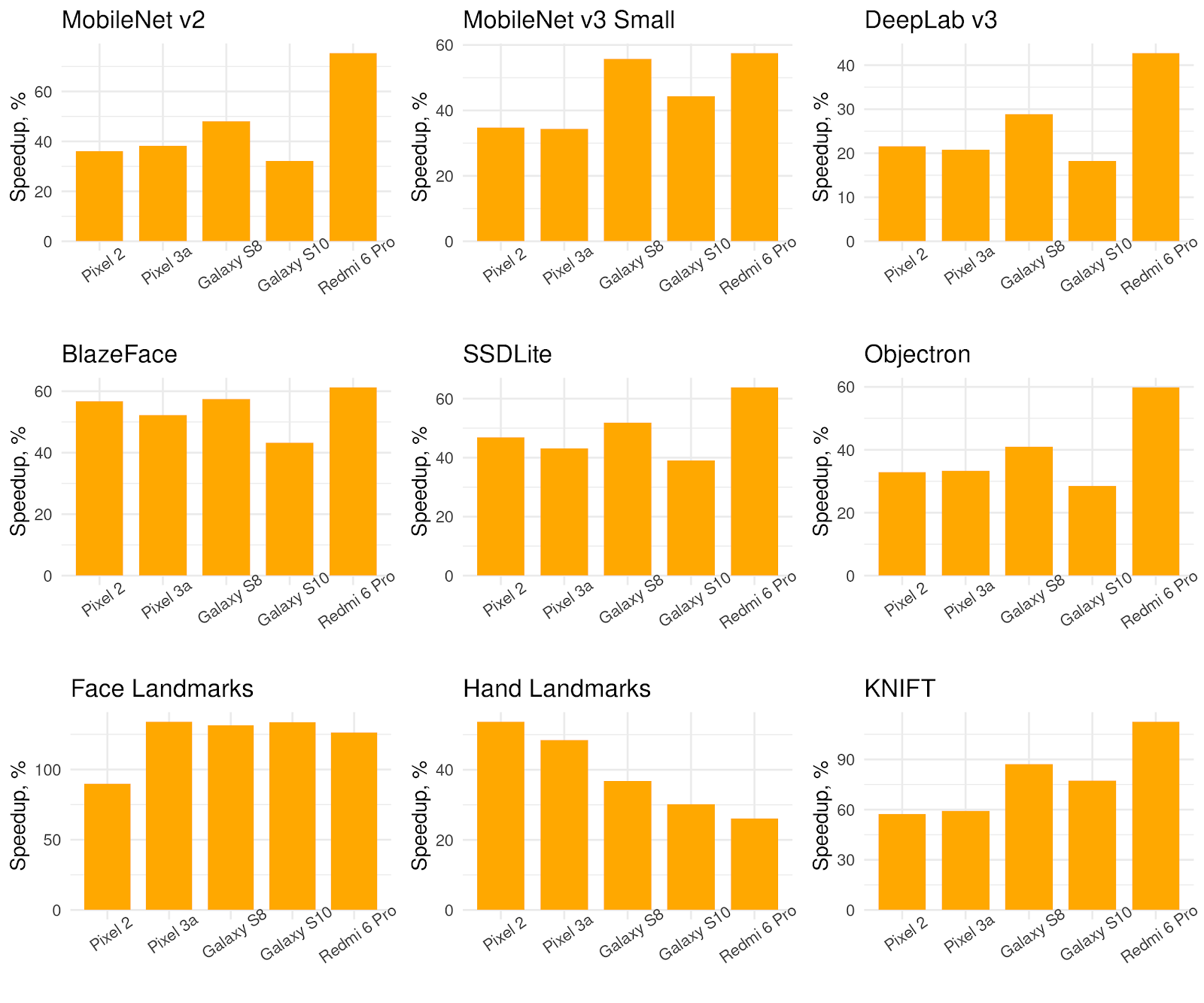 Single-threaded inference speedup with TensorFlow Lite with the XNNPACK backend compared to the default backend across 5 mobile phones. Higher numbers are better.
Single-threaded inference speedup with TensorFlow Lite with the XNNPACK backend compared to the default backend across 5 mobile phones. Higher numbers are better.
 Single-threaded inference speedup with TensorFlow Lite with the XNNPACK backend compared to the default backend across 5 desktop, laptop, and embedded devices. Higher numbers are better.
How Can I Use It?The XNNPACK backend is already included in pre-built TensorFlow Lite 2.3 binaries, but requires an explicit runtime opt-in to enable it. We’re working to enable it by default in a future release. Opt-in to XNNPACK backend on Android/JavaPre-built TensorFlow Lite 2.3 Android archive (AAR) already include XNNPACK, and it takes only a single line of code to enable it in Interpreter.Options object: Interpreter.Options interpreterOptions = new Interpreter.Options();
interpreterOptions.setUseXNNPACK(true);
Interpreter interpreter = new Interpreter(model, interpreterOptions);Opt-in to XNNPACK backend on iOS/SwiftPre-built TensorFlow Lite 2.3 CocoaPods for iOS similarly include XNNPACK, and a mechanism to enable it in the InterpreterOptions class: var options = InterpreterOptions()
options.isXNNPackEnabled = true
var interpreter = try Interpreter(modelPath: "model/path", options: options)Opt-in to XNNPACK backend on iOS/Objective-COn iOS XNNPACK inference can be enabled from Objective-C as well via a new property in the TFLInterpreterOptions class: TFLInterpreterOptions *options = [[TFLInterpreterOptions alloc] init];
options.useXNNPACK = YES;
NSError *error;
TFLInterpreter *interpreter =
[[TFLInterpreter alloc] initWithModelPath:@"model/path"
options:options
error:&error];Opt-in to XNNPACK backend on Windows, Linux, and MacXNNPACK backend on Windows, Linux, and Mac is enabled via a build-time opt-in mechanism. When building TensorFlow Lite with Bazel, simply add --define tflite_with_xnnpack=true, and the TensorFlow Lite interpreter will use the XNNPACK backend by default. Try out XNNPACK with your TensorFlow Lite modelYou can use the TensorFlow Lite benchmark tool and measure your TensorFlow Lite model performance with XNNPACK. You only need to enable XNNPACK by the --use_xnnpack=true flag as below, even if the benchmark tool is built without the --define tflite_with_xnnpack=true Bazel option. adb shell /data/local/tmp/benchmark_model \
--graph=/data/local/tmp/mobilenet_quant_v1_224.tflite \
--use_xnnpack=true \
--num_threads=4Which Operations Are Accelerated?The XNNPACK backend currently supports a subset of floating-point TensorFlow Lite operators (see documentation for details and limitations). XNNPACK supports both 32-bit floating-point models and models using 16-bit floating-point quantization for weights, but not models with fixed-point quantization in weights or activations. However, you do not have to constrain your model to the operators supported by XNNPACK: any unsupported operators would transparently fall-back to the default implementation in TensorFlow Lite. Future WorkThis is just the first version of the XNNPACK backend. Along with community feedback, we intend to add the following improvements: Integration of the Fast Sparse ConvNets algorithms
Half-precision inference on the recent ARM processors
Quantized inference in fixed-point representation
We encourage you to leave your thoughts and comments on our GitHub and StackOverflow pages. AcknowledgementsWe would like to thank Frank Barchard, Chao Mei, Erich Elsen, Yunlu Li, Jared Duke, Artsiom Ablavatski, Juhyun Lee, Andrei Kulik, Matthias Grundmann, Sameer Agarwal, Ming Guang Yong, Lawrence Chan, Sarah Sirajuddin.
Single-threaded inference speedup with TensorFlow Lite with the XNNPACK backend compared to the default backend across 5 desktop, laptop, and embedded devices. Higher numbers are better.
How Can I Use It?The XNNPACK backend is already included in pre-built TensorFlow Lite 2.3 binaries, but requires an explicit runtime opt-in to enable it. We’re working to enable it by default in a future release. Opt-in to XNNPACK backend on Android/JavaPre-built TensorFlow Lite 2.3 Android archive (AAR) already include XNNPACK, and it takes only a single line of code to enable it in Interpreter.Options object: Interpreter.Options interpreterOptions = new Interpreter.Options();
interpreterOptions.setUseXNNPACK(true);
Interpreter interpreter = new Interpreter(model, interpreterOptions);Opt-in to XNNPACK backend on iOS/SwiftPre-built TensorFlow Lite 2.3 CocoaPods for iOS similarly include XNNPACK, and a mechanism to enable it in the InterpreterOptions class: var options = InterpreterOptions()
options.isXNNPackEnabled = true
var interpreter = try Interpreter(modelPath: "model/path", options: options)Opt-in to XNNPACK backend on iOS/Objective-COn iOS XNNPACK inference can be enabled from Objective-C as well via a new property in the TFLInterpreterOptions class: TFLInterpreterOptions *options = [[TFLInterpreterOptions alloc] init];
options.useXNNPACK = YES;
NSError *error;
TFLInterpreter *interpreter =
[[TFLInterpreter alloc] initWithModelPath:@"model/path"
options:options
error:&error];Opt-in to XNNPACK backend on Windows, Linux, and MacXNNPACK backend on Windows, Linux, and Mac is enabled via a build-time opt-in mechanism. When building TensorFlow Lite with Bazel, simply add --define tflite_with_xnnpack=true, and the TensorFlow Lite interpreter will use the XNNPACK backend by default. Try out XNNPACK with your TensorFlow Lite modelYou can use the TensorFlow Lite benchmark tool and measure your TensorFlow Lite model performance with XNNPACK. You only need to enable XNNPACK by the --use_xnnpack=true flag as below, even if the benchmark tool is built without the --define tflite_with_xnnpack=true Bazel option. adb shell /data/local/tmp/benchmark_model \
--graph=/data/local/tmp/mobilenet_quant_v1_224.tflite \
--use_xnnpack=true \
--num_threads=4Which Operations Are Accelerated?The XNNPACK backend currently supports a subset of floating-point TensorFlow Lite operators (see documentation for details and limitations). XNNPACK supports both 32-bit floating-point models and models using 16-bit floating-point quantization for weights, but not models with fixed-point quantization in weights or activations. However, you do not have to constrain your model to the operators supported by XNNPACK: any unsupported operators would transparently fall-back to the default implementation in TensorFlow Lite. Future WorkThis is just the first version of the XNNPACK backend. Along with community feedback, we intend to add the following improvements: Integration of the Fast Sparse ConvNets algorithms
Half-precision inference on the recent ARM processors
Quantized inference in fixed-point representation
We encourage you to leave your thoughts and comments on our GitHub and StackOverflow pages. AcknowledgementsWe would like to thank Frank Barchard, Chao Mei, Erich Elsen, Yunlu Li, Jared Duke, Artsiom Ablavatski, Juhyun Lee, Andrei Kulik, Matthias Grundmann, Sameer Agarwal, Ming Guang Yong, Lawrence Chan, Sarah Sirajuddin.
|
【本文地址】